
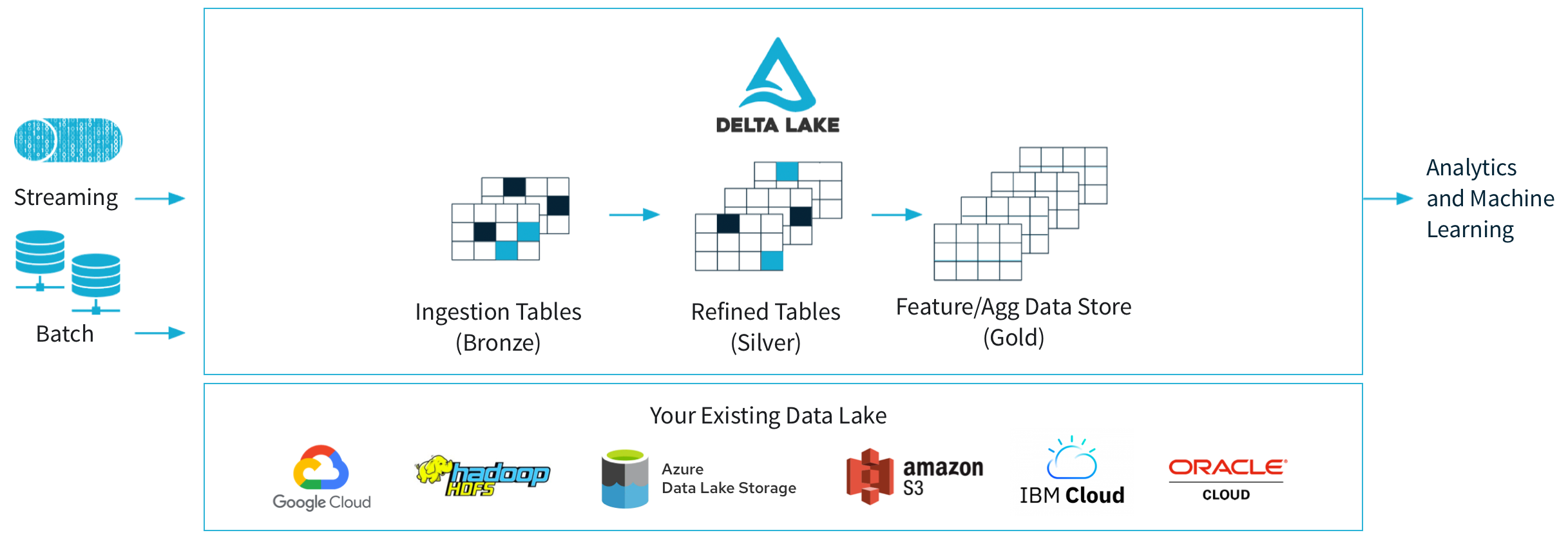
DeltaLakeとは
- DeltaLakeはクラウドストレージ(S3,AzureDataLake,GCS)やHDFSなどのストレージ上に構築されるOSSのストレージレイヤーです。OSSのフォーマットのParquetを拡張していて、ACID準拠のトランザクション、バージョン管理、タイムトラベルなどの高度な機能を提供しています。また、安価なクラウドストレージに構築するため信頼性や耐久性を持ちつつ、ビッグデータソリューションのベンチマークであるTPC-DSの100TBクラスで世界記録を更新しており、圧倒的なコストパフォーマンスを実現しています。
- Databricks上で利用するのが一般的ですが、DeltaLakeは活発なオープンソースコミュニティにより拡張が続けられており、Linux Foundationプロジェクトによって最新バージョンのDeltaLake2.0ですべての機能がOSS化されています。

DeltaLakeテーブルの作成
DatabricksのDBFSから1千万件のデモデータをロードしてテーブルを作成しています
DROP TABLE IF EXISTS people_10m;
CREATE TABLE IF NOT EXISTS people_10m
AS SELECT * FROM delta.`/databricks-datasets/learning-spark-v2/people/people-10m.delta`;スキーマと場所(LOCATION)を指定していないため、hive_metastoreのdefaultスキーマ上のmanaged tableとして作成されます。managed tableはDBFSルートパス上の/user/hive/warehouseの下にテーブル名のフォルダが作成されます。
どこのパスにファイルが管理されているのかは以下の構文で確認することができます。
DESCRIBE DETAIL people_10m;この例ではdelta形式のデータを読み込んだため、スキーマが適用されていますが、事前にスキーマを指定してからデータをロードすることで、スキーマを強制させることができます。
DROP TABLE people_10m; -- managed tableの場合データもテーブルと同時に削除されます
CREATE TABLE people_10m (
id INT,
firstName STRING,
middleName STRING,
lastName STRING,
gender STRING,
birthDate TIMESTAMP,
ssn STRING,
salary INT
);
INSERT INTO people_10m
SELECT * FROM delta.`/databricks-datasets/learning-spark-v2/people/people-10m.delta`;スキーマの強制
CSVなどのデータを読み込む場合にはスキーマ(データの形式)を指定しておく場合があります。
スキーマを指定しない場合、CSVデータからスキーマを推測(inferSchema)します。
%python
# dbtuilsでCSVデータを作成する
dbutils.fs.rm("dbfs:/tmp/people10m.csv", True)
dbutils.fs.put("dbfs:/tmp/people10m.csv", """
id|firstName|middleName|lastName|gender|birthDate|ssn|salary
10000001|hoge|fuga|baz|M|1975-01-01T04:00:00|999-99-9999|1000000
"""
)
df = spark.read.option('header','true') \
.option('delimiter','|') \
.csv('dbfs:/tmp/people10m.csv')
df.write.format("delta") \
.mode("append") \
.save("dbfs:/user/hive/warehouse/people_10m")
# CSVからデータをロードするとid列がStringTypeとして推測されてしまい、エラーとなってしまう
#AnalysisException: Failed to merge fields 'id' and 'id'. Failed to merge incompatible data types IntegerType and StringType以下のようにスキーマを指定してデータをロードします
%python
from pyspark.sql.types import *
schema = StructType([
StructField('id', IntegerType(), True),
StructField('firstName', StringType(), True),
StructField('middleName', StringType(), True),
StructField('lastName', StringType(), True),
StructField('gender', StringType(), True),
StructField('birthDate', TimestampType(), True),
StructField('ssn', StringType(), True),
StructField('salary', IntegerType(), True)
])
df = spark.read.option('header','true') \
.option('delimiter','|') \
.schema(schema) \
.csv('dbfs:/tmp/people10m.csv')
df.write.format("delta") \
.mode("append") \
.save("dbfs:/user/hive/warehouse/people_10m")以下のようにCSVファイルからデータを登録することができました。

次にスキーマに一致しない(salary列に文字列を含む)CSVデータを作成してロードをしてみます。FAILFASTモードを設定しているため、NumberformatExceptionがスローされ、テーブルにデータは追加されません。
%python
# dbtuilsでCSVデータを作成する
dbutils.fs.rm("dbfs:/tmp/invalid_people.csv", True)
dbutils.fs.put("dbfs:/tmp/invalid_people.csv", """
id|firstName|middleName|lastName|gender|birthDate|ssn|salary
10000002|hoge|fuga|baz|M|1975-01-01T04:00:00|999-99-9999|$10000
"""
)
df = spark.read.option('header','true') \
.option('delimiter','|') \
.option('mode', 'FAILFAST') \
.schema(schema) \
.csv('dbfs:/tmp/invalid_people.csv')
df.write.format("delta") \
.mode("append") \
.save("dbfs:/user/hive/warehouse/people_10m")
# 以下の例外がスローされる
Caused by: org.apache.spark.sql.catalyst.util.BadRecordException: java.lang.NumberFormatException: For input string: "$10000"次にcityカラムを追加したCSVファイルをロードしてみます。
今度はスキーマの定義とデータは一致していますが、テーブル定義の列情報と不一致しているため、エラーとなります。
%python
# dbtuilsでCSVデータを作成する
dbutils.fs.rm("dbfs:/tmp/add_city_people.csv", True)
dbutils.fs.put("dbfs:/tmp/add_city_people.csv", """
id|firstName|middleName|lastName|gender|birthDate|ssn|salary|city
10000002|hoge|fuga|baz|M|1975-01-01T04:00:00|999-99-9999|1000000|tokyo
"""
)
from pyspark.sql.types import *
schema = StructType([
StructField('id', IntegerType(), True),
StructField('firstName', StringType(), True),
StructField('middleName', StringType(), True),
StructField('lastName', StringType(), True),
StructField('gender', StringType(), True),
StructField('birthDate', TimestampType(), True),
StructField('ssn', StringType(), True),
StructField('salary', IntegerType(), True),
StructField('city', StringType(), True)
])
df = spark.read.option('header','true') \
.option('delimiter','|') \
.option('mode', 'FAILFAST') \
.schema(schema) \
.csv('dbfs:/tmp/add_city_people.csv')
df.write.format("delta") \
.mode("append") \
.save("dbfs:/user/hive/warehouse/people_10m")
# 以下の例外がスローされる
AnalysisException: A schema mismatch detected when writing to the Delta table (Table ID: 3fd9169a-2f49-48c8-9fd2-35d954a6e07d).
To enable schema migration using DataFrameWriter or DataStreamWriter, please set:
'.option("mergeSchema", "true")'.エラーメッセージに表示されているとおり、mergeSchemaオプションを指定することでスキーマが拡張されて登録することができます。既存のレコードのcityカラムの値はnullになっています。
%python
# dbtuilsでCSVデータを作成する
dbutils.fs.rm("dbfs:/tmp/add_city_people.csv", True)
dbutils.fs.put("dbfs:/tmp/add_city_people.csv", """
id|firstName|middleName|lastName|gender|birthDate|ssn|salary|city
10000002|hoge|fuga|baz|M|1975-01-01T04:00:00|999-99-9999|1000000|tokyo
"""
)
from pyspark.sql.types import *
schema = StructType([
StructField('id', IntegerType(), True),
StructField('firstName', StringType(), True),
StructField('middleName', StringType(), True),
StructField('lastName', StringType(), True),
StructField('gender', StringType(), True),
StructField('birthDate', TimestampType(), True),
StructField('ssn', StringType(), True),
StructField('salary', IntegerType(), True),
StructField('city', StringType(), True)
])
df = spark.read.option('header','true') \
.option('delimiter','|') \
.option('mode', 'FAILFAST') \
.schema(schema) \
.csv('dbfs:/tmp/add_city_people.csv')
df.write.format("delta") \
.mode("append") \
.option('mergeSchema', 'true') \
.save("dbfs:/user/hive/warehouse/people_10m")
データ型の変更
カラムのデータ型を変更するにはoverwriteSchemaでキャスト済のデータで再作成します。
UnityCatalogを適用している場合は、以下のように3レベルの記述法でメタストア、スキーマ、テーブルを指定することができます。
%python
from pyspark.sql.functions import col
spark.read.table("hive_metastore.default.people_10m") \
.withColumn("salary", col("salary").cast("string")) \
.write.mode("overwrite").option("overwriteSchema", "true") \
.saveAsTable("hive_metastore.default.people_10m")以下のようにsalaryカラムがString型に変更されていることが確認できます。
SHOW CREATE TABLE hive_metastore.default.people_10m;
-- 以下が表示されます
CREATE TABLE hive_metastore.default.people_10m ( id INT, firstName STRING, middleName STRING, lastName STRING, gender STRING, birthDate TIMESTAMP, ssn STRING, salary STRING, city STRING) USING delta TBLPROPERTIES ( 'delta.minReaderVersion' = '1', 'delta.minWriterVersion' = '2')文字列を更新することができます。
UPDATE people_10m SET salary = "100000$" WHERE id = 10000002タイムトラベル
DeltaLakeはテーブルの更新履歴として、バージョン・操作・ユーザーなどを管理しています。DESCRIBE HISTORY文を使用して表示することができます。
以前のバージョンのデータをクエリすることができます。DESCRIBE HISTORYで表示されたtimestampもしくはversionを指定してクエリすることができます。
-- cityカラムを追加する前のデータを取得する
SELECT * FROM people_10m VERSION AS OF 2
-- timestampを指定する場合
SELECT * FROM people_10m TIMESTAMP AS OF '2022-11-26 12:39:52'以前の状態にレストアすることができます。タイムトラベルと同じく、RESTORE文にtimestampもしくはversionを指定します。
RESTORE people_10m VERSION AS OF 2Z-Ordering
Deltalakeのトランザクションログには、各ファイルにあるカラムの最小値・最大値などの統計情報を管理していて、クエリ条件によっては統計情報の値範囲外のデータをスキップしてクエリを効率化する機能(データスキップ)があります。
Z-Orderingとは、指定したカラムの関連するデータを同じファイルセットに格納しなおすことで、効率的にデータスキップを実行させることが可能になる機能です。
最初に1千万件のpeople_10mデータをファイルから作り直してファイルを確認してみます。
DROP TABLE IF EXISTS people_10m; -- テーブル削除と同時にファイルも全て削除されます
CREATE TABLE IF NOT EXISTS people_10m
AS SELECT * FROM delta.`/databricks-datasets/learning-spark-v2/people/people-10m.delta`;以下のdbutilsコマンドでpeople_10mテーブルのファイルを確認することができます。
58MByte程度の4つのファイルが出力されています。DESCRIBE DETAIL people_10mを実行することでも、numFilesカラムの値でファイル数を確認することもできます。
%python
display(dbutils.fs.ls("dbfs:/user/hive/warehouse/people_10m"))
birthDateを条件にクエリを実行してみます。
Z-Orderingによる最適化前の状態では、4つのファイルをスキャンしていることが確認できます。(number of files readが4)
select * from people_10m where birthDate between '1975-01-02 00:00:00' and '1975-01-03 00:00:00' 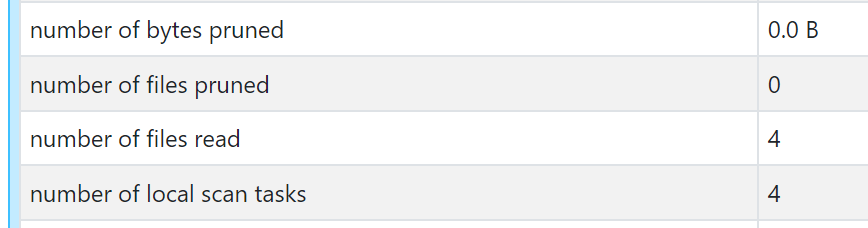
以下はOptimizeを実行する際にファイルをマージするサイズを指定しています。(Z-Orderingの検証のためにファイルをマージさせたくないので、58MByteを指定しています)
SET spark.databricks.delta.optimize.maxFileSize = 58720256;以下のコマンドでZ-Orderingによる最適化を実行します。
optimize people_10m zorder by (birthDate)同じクエリを実行して確認してみます。ファイルプルーニング(number of files pruned)が3、実際にスキャンしたファイル数(number of files read)が1になったことが確認できます。
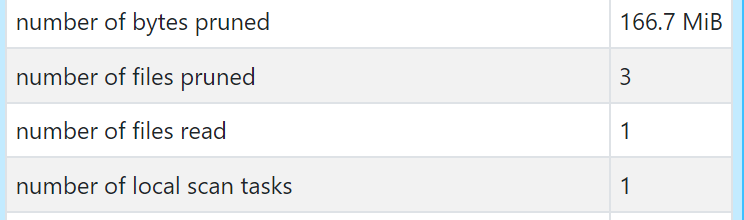
このようにZ-Ordering機能でスキャンするファイルを少なくすることでパフォーマンスの向上が見込めます。また、Optimizeで小さなファイルを指定したサイズ(デフォルトでは、1GByteです)にマージすることでも読み込むファイル数を削減することができます。
おわりに
まだまだ検証できていない多数の機能がありますが、少しずつ更新していきたいと思います。