
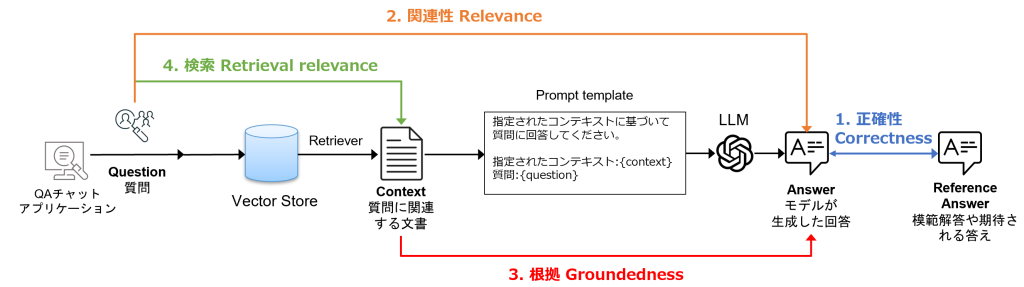
LLM-as-a-Judge による評価
- LLM-as-a-Judgeとは、LLMをテキスト生成モデルだけでなく、「評価者としても活用する」という評価手法です
- 以下4種類の組み合わせを比較し、LLMに評価をさせます
- 正確性:LLMの回答結果と期待される回答を比べてどの程度正しいか
- 関連性:LLMの回答結果が質問に対してどれだけ適切に対応しているか
- 根拠:LLMの回答結果が取得されたコンテキスト(質問に関連する文書)とどの程度一致するか(幻覚が発生していないか)
- 検索:質問と取得されたコンテキスト(質問に関連する文書)がどの程度関連しているか
- これら4つの組み合わせをLLMにより測定させることで、RAGシステムにおけるドキュメント取得の妥当性から最終回答の有用性・正確さまで、多角的に評価することができます。これらの評価結果より問題を特定し、改善活動を行います
評価用プロンプトの例
- 以下は、1.正確性の測定結果をLLMに回答させるためのプロンプトの例です。測定結果は、回答が正解かどうか(True or False)の真偽値と採点理由を文章で出力させます
あなたはクイズを採点する教師です。
これから、QUESTION(問題文)、GROUND TRUTH(正解)、STUDENT ANSWER(生徒の回答)が与えられます。
以下の採点基準に従ってください:
生徒の回答は、正解(GROUND TRUTH)に照らした「事実ベースの正確性」のみに基づいて採点してください。
生徒の回答に、相互に矛盾する記述がないか確認してください。
生徒の回答が正解よりも多くの情報を含んでいても、正解と事実的に矛盾していなければ問題ありません。
正確性(Correctness)について:
値が True の場合: 生徒の回答が上記の全ての基準を満たしていることを意味します。
値が False の場合: 生徒の回答が上記のいずれかの基準を満たしていないことを意味します。
あなたの推論と結論が正しいことを示すために、ステップ・バイ・ステップで理由を説明してください。
最初に正解だけをただ提示するのは避けてください。
QUESTION: {inputs['question']}
GROUND TRUTH ANSWER: {reference_outputs['answer']}
STUDENT ANSWER: {outputs['answer']}
入力パラメータ
- QUESTION:
{inputs['question']}など、ユーザーが入力した質問の内容を格納 - GROUND TRUTH ANSWER:
{reference_outputs['answer']}ここには模範解答や期待される回答を格納 - STUDENT ANSWER:
{outputs['answer']}モデルが生成した回答を格納
LangSmithで評価する
- LangSmithでは以下のステップで評価を実行します
- 質問とそれに対する予想される回答を含むデータセットを作成する
- これらの質問に対してRAGアプリケーションを実行する
- 評価ツールを実行後、評価結果の一覧から結果を参照する
- 実装コードはGitHubに公開しています
- 実行すると、評価データセットを作成して4つの組み合わせで評価を行い、Experimentsとして記録されます
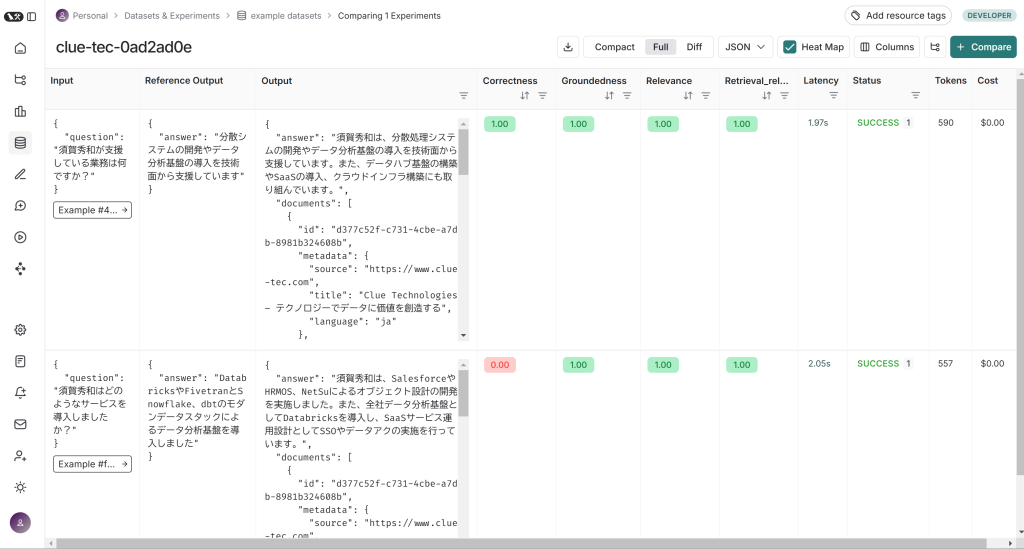
- LLMによる採点の結果、正解ではないと判断された結果(上記の赤色のスコアが0の項目)についてトレースログを参照することで、LLMの評価実行時の採点理由を確認することができます
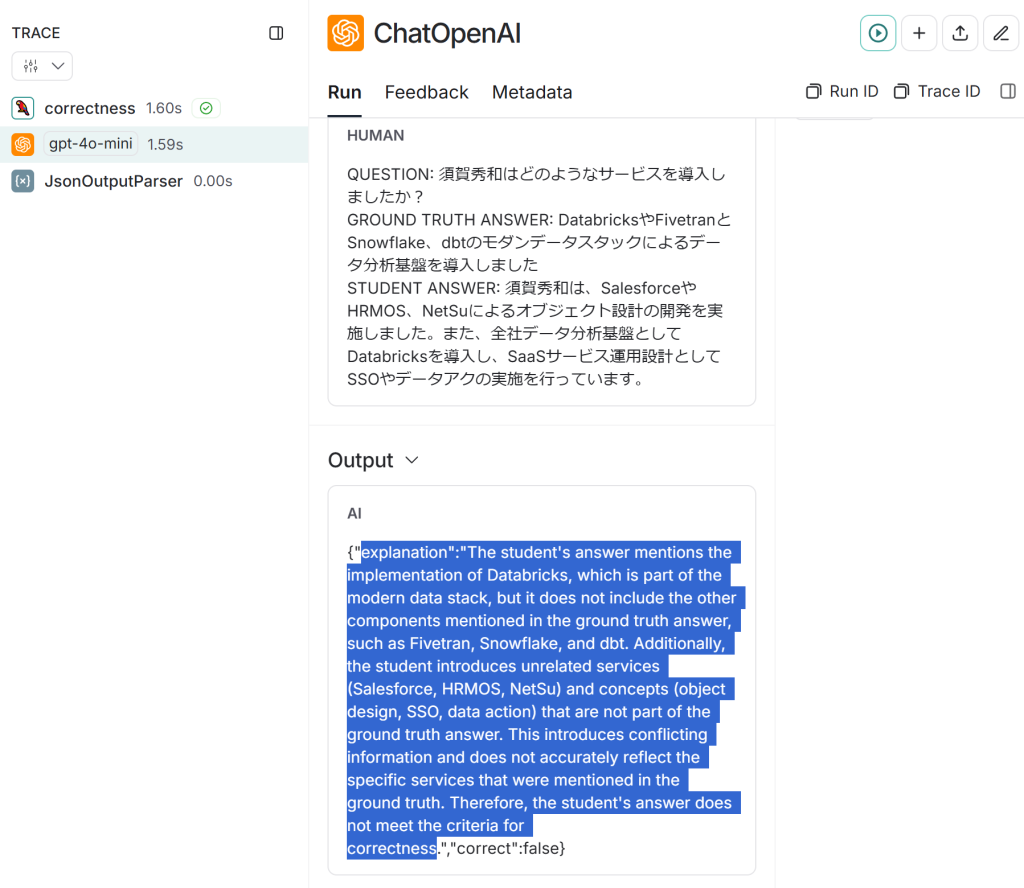
- 採点理由はexplanationに出力される
まとめ
- 今回は公式のチュートリアルに沿ってLangSmithの評価機能を試してみました。RAGアプリケーションの複雑化・LLMの多様化が進む中、LangSmithを使うことで開発と評価のワークフローを効率化し、より信頼性の高いLLMアプリケーションを構築できるようになります